Multimodal Diffusion Transformer with Memory Bank for Scalable Long-Duration Talking Video Generation
2Institute of Automation, Chinese Academy of Sciences
3Beijing National Research Center for Information Science and Technology, Tsinghua University
4Department of Automation, Tsinghua University
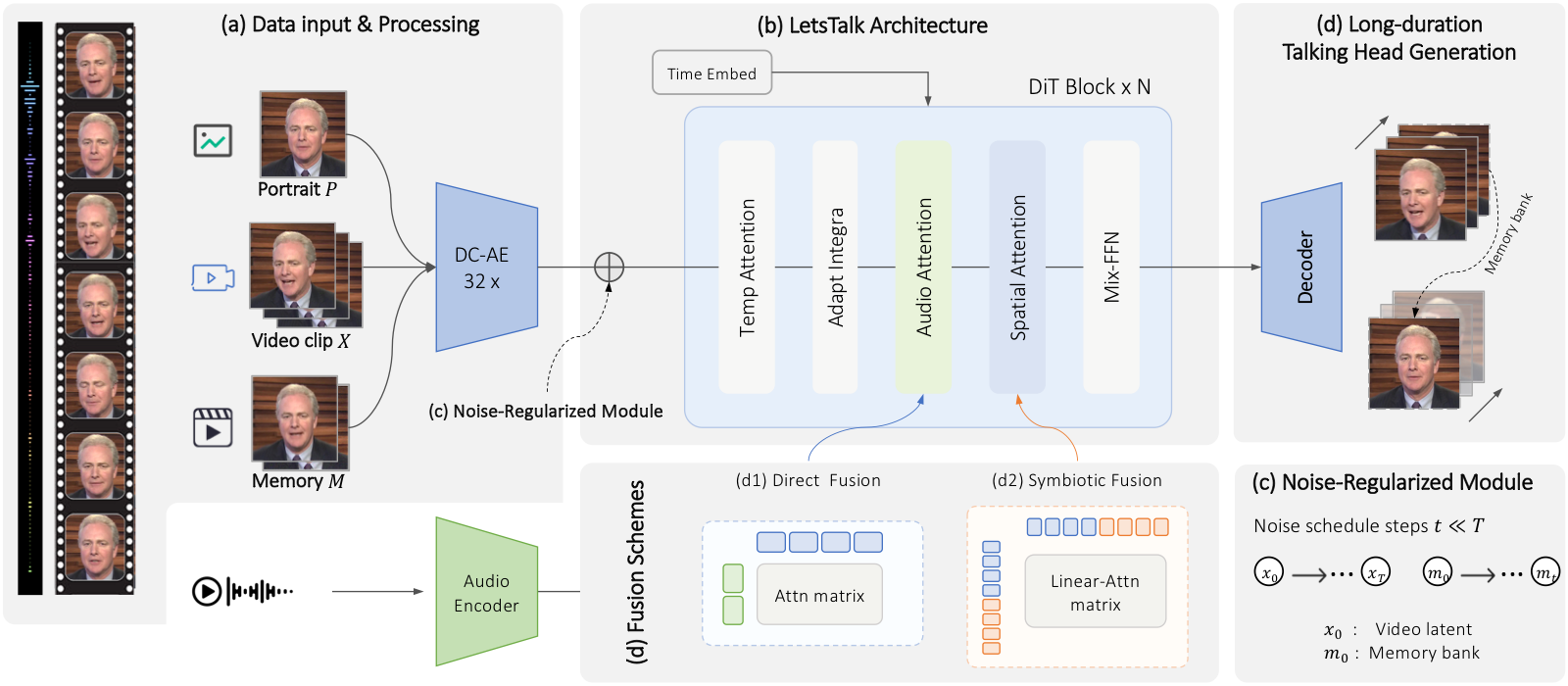
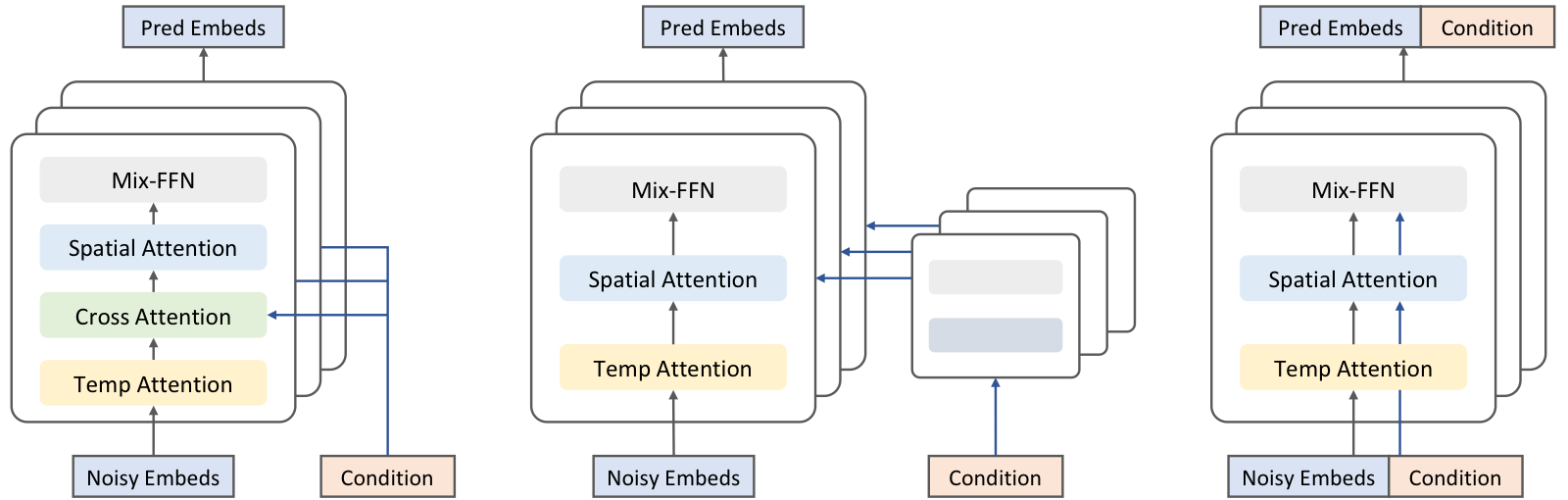
TL;DR: We propose LetsTalk, a diffusion transformer framework for audio-driven portrait animation. LetsTalk combines a deep compression autoencoder, an efficient spatiotemporal transformer, asymmetric multimodal fusion, and a noise-regularized memory bank to generate realistic, temporally coherent, and scalable long-duration talking videos.

Given a single reference portrait and driving audio, LetsTalk produces realistic talking videos with stable identity, precise audio-animation alignment, and long-duration temporal coherence. The accepted TMM version further extends the original system with a memory bank mechanism for scalable long-video generation.