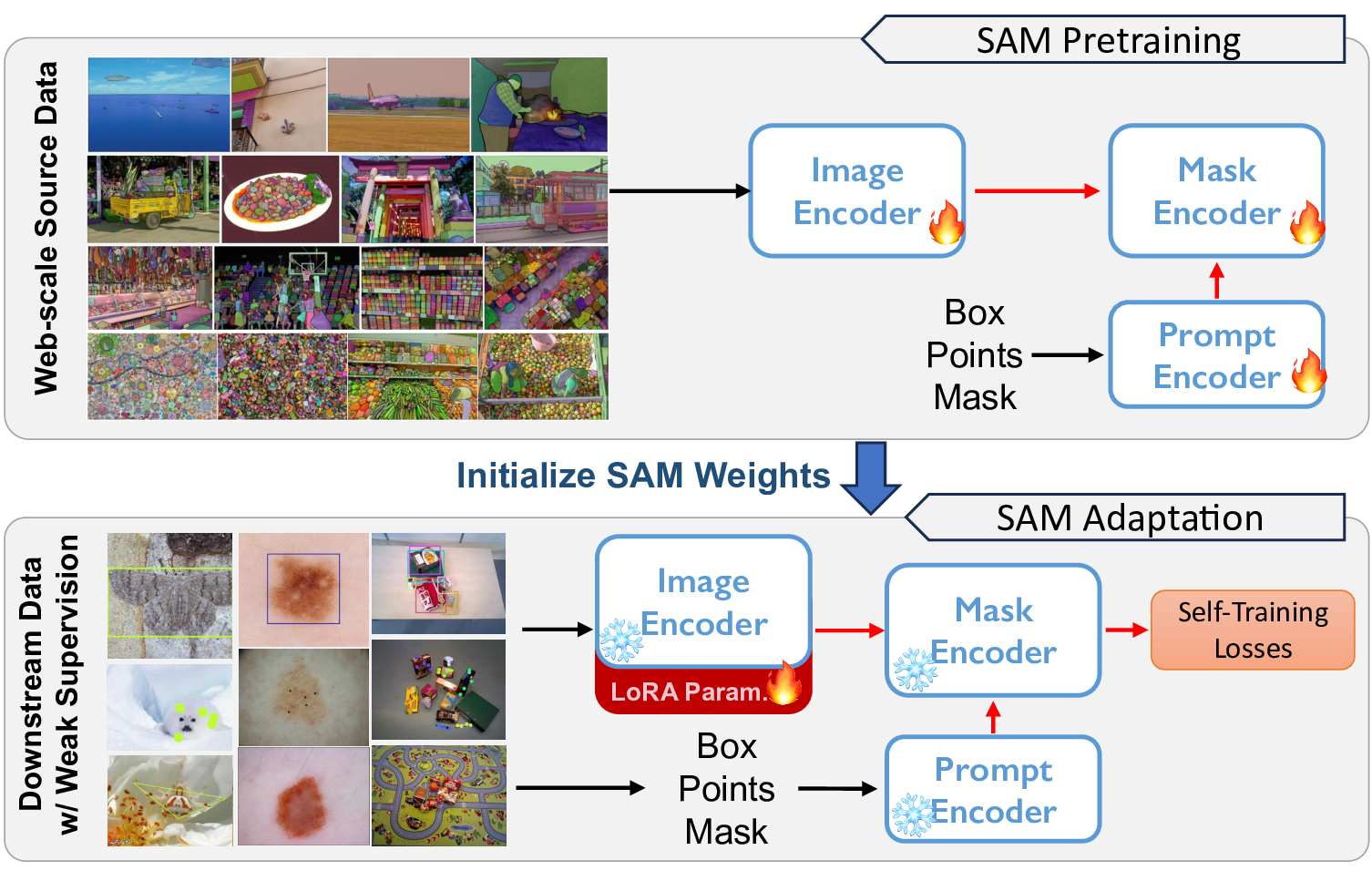
Dataset used in this work.
|
Natural Images |
Corrupted Images |
Medical Images |
Camouflaged Objects |
Robotic Images |
| Dataset |
COCO |
Pascal VOC |
COCO-C |
kvasir-SEG |
ISIC |
CHAMELEON |
CAMO |
COD10K |
OCID |
OSD |
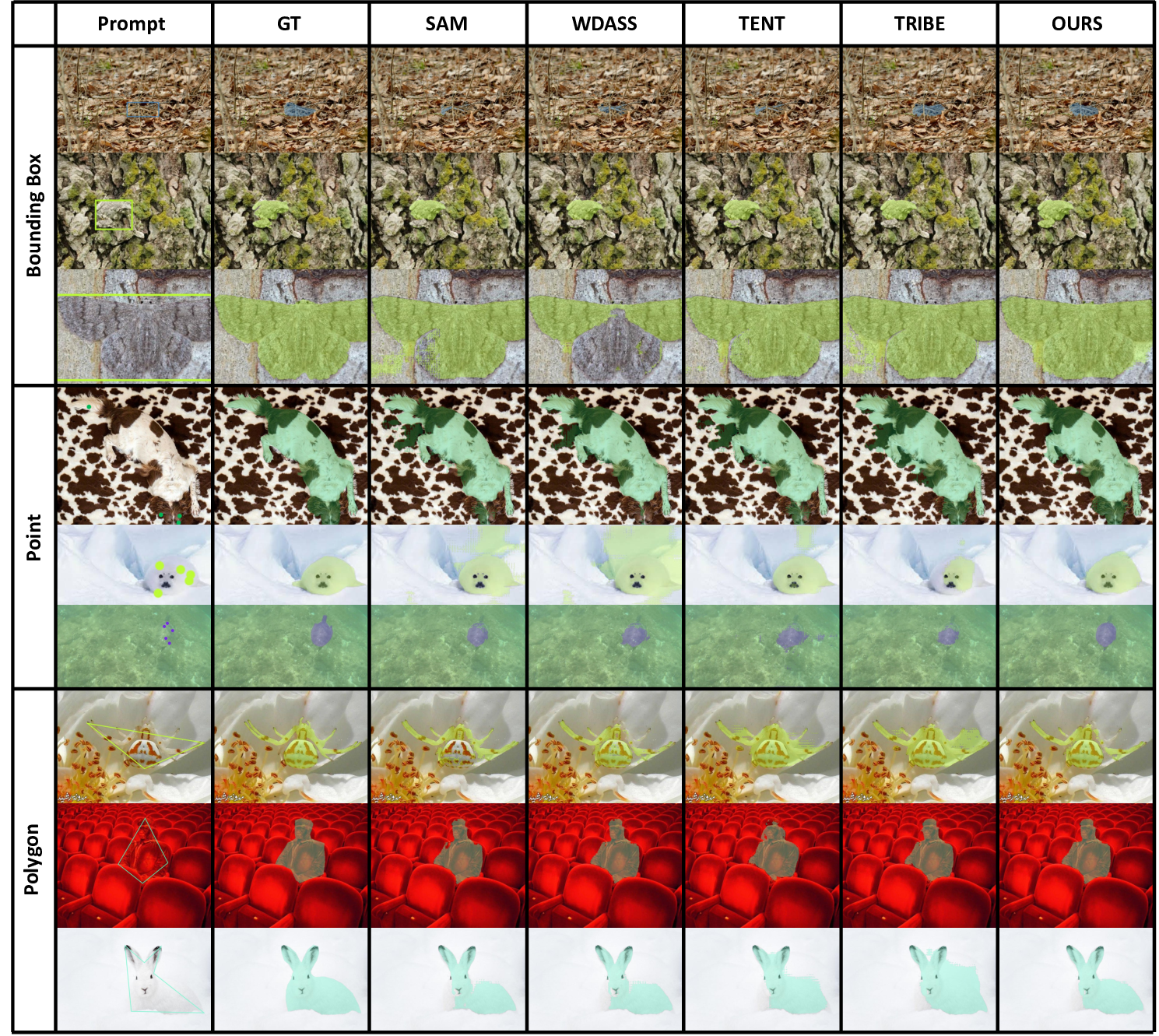
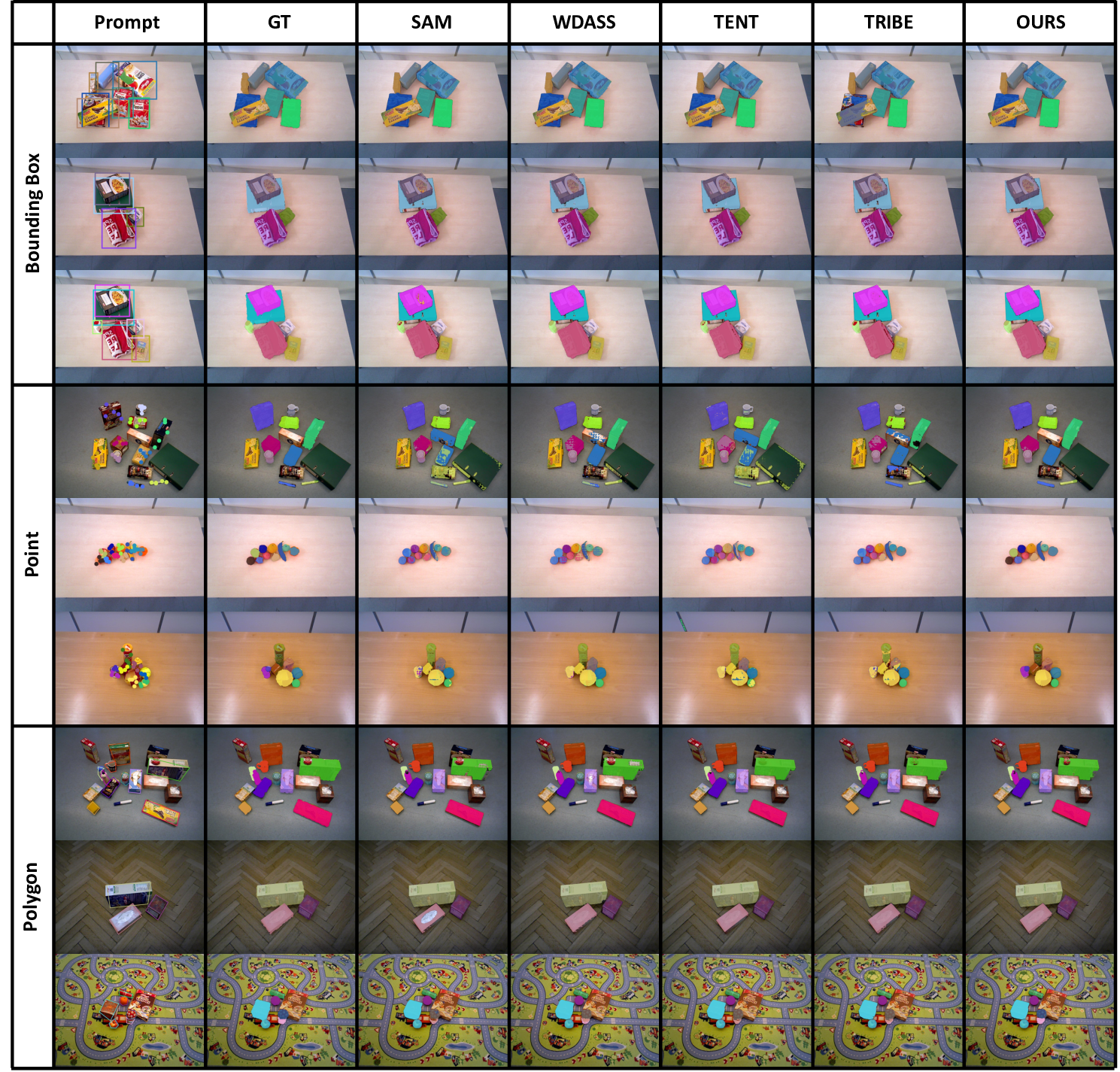
Table 1: Adaptation results on COCO-C dataset using bounding box prompt.
| Method | Brit | Contr | Defoc | Elast | Fog | Frost | Gauss | Glass | Impul | Jpeg | Motn | Pixel | Shot | Snow | Zoom | Avg |
|---|
| Direct | 72.83 | 57.34 | 64.47 | 69.36 | 72.39 | 70.50 | 67.20 | 64.43 | 67.65 | 68.23 | 62.72 | 68.60 | 67.44 | 69.02 | 58.80 | 66.73 |
|---|
| TENT | 76.02 | 61.51 | 67.48 | 70.88 | 74.89 | 73.88 | 69.01 | 67.10 | 69.28 | 70.25 | 65.45 | 70.81 | 69.96 | 72.37 | 62.59 | 69.43 |
|---|
| SHOT | 73.84 | 59.09 | 65.91 | 69.57 | 73.98 | 72.51 | 68.30 | 66.09 | 68.61 | 69.45 | 64.56 | 70.48 | 68.77 | 71.03 | 60.17 | 68.16 |
|---|
| Soft Teacher | 73.90 | 62.12 | 65.41 | 71.32 | 72.16 | 73.27 | 68.84 | 67.49 | 68.73 | 70.18 | 66.88 | 69.79 | 70.08 | 73.33 | 64.88 | 69.23 |
|---|
| TRIBE | 76.40 | 60.86 | 66.19 | 72.72 | 75.08 | 75.14 | 70.34 | 66.66 | 70.83 | 72.42 | 65.94 | 70.24 | 70.66 | 74.22 | 64.56 | 70.15 |
|---|
| DePT | 69.15 | 57.26 | 59.08 | 66.80 | 58.73 | 66.75 | 66.78 | 62.74 | 65.65 | 66.39 | 61.66 | 66.65 | 67.57 | 66.62 | 58.21 | 64.42 |
|---|
| WDASS | 76.21 | 60.57 | 67.07 | 72.34 | 75.97 | 74.63 | 69.84 | 67.88 | 69.92 | 71.36 | 66.25 | 71.99 | 70.32 | 72.25 | 63.61 | 70.01 |
|---|
| OURS | 78.50 | 61.05 | 66.99 | 73.93 | 77.09 | 76.10 | 72.02 | 68.21 | 71.29 | 72.77 | 66.33 | 70.90 | 70.28 | 75.07 | 65.33 | 71.05 |
|---|
| Supervised | 78.86 | 74.81 | 72.04 | 74.32 | 78.01 | 77.14 | 73.43 | 72.12 | 74.08 | 75.30 | 71.39 | 75.15 | 74.25 | 76.34 | 68.04 | 74.35 |
|---|
Table 2: Adaptation results on natural clean image datasets.
| Method | COCO 2017 | Pascal VOC |
|---|
| box | point | poly | box | point | poly |
|---|
| Direct | 74.29 | 55.06 | 65.64 | 69.21 | 69.21 | 60.79 |
|---|
| TENT | 78.21 | 52.99 | 71.51 | 80.24 | 74.97 | 65.03 |
|---|
| SHOT | 75.18 | 58.46 | 69.26 | 79.80 | 74.26 | 63.38 |
|---|
| Soft Teacher | 75.94 | 43.36 | 68.27 | 72.93 | 56.09 | 62.20 |
|---|
| TRIBE | 77.56 | 49.56 | 70.99 | 78.87 | 69.21 | 65.39 |
|---|
| DePT | 71.00 | 37.35 | 63.27 | 74.09 | 42.99 | 59.94 |
|---|
| WDASS | 77.29 | 60.55 | 70.19 | 80.12 | 76.15 | 66.98 |
|---|
| OURS | 80.12 | 62.09 | 72.33 | 80.27 | 74.15 | 66.72 |
|---|
| Supervised | 81.50 | 69.77 | 73.39 | 81.23 | 76.98 | 71.32 |
|---|
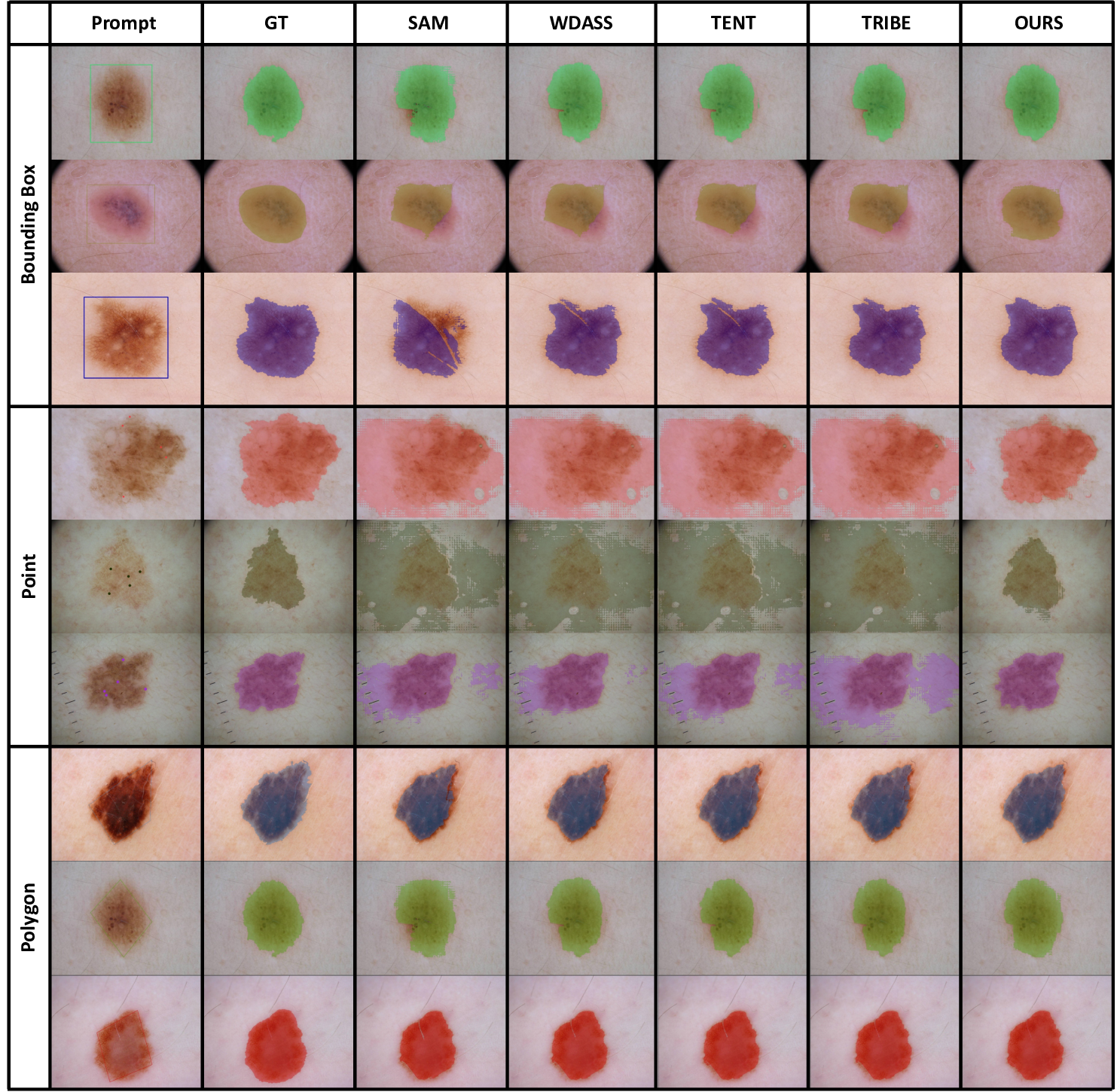
Table 3: Adaptation results on medical image segmentation datasets.
| Method | kvasir-SEG | ISIC |
|---|
| box | point | poly | box | point | poly |
|---|
| Direct | 81.59 | 62.30 | 54.03 | 66.74 | 53.42 | 62.82 |
|---|
| TENT | 82.47 | 61.84 | 62.97 | 71.76 | 53.46 | 67.12 |
|---|
| SHOT | 82.30 | 63.76 | 61.34 | 71.99 | 55.99 | 66.86 |
|---|
| Soft Teacher | 84.12 | 73.53 | 58.15 | 75.74 | 54.95 | 72.29 |
|---|
| TRIBE | 85.05 | 73.03 | 64.61 | 72.61 | 50.36 | 67.99 |
|---|
| DePT | 81.91 | 52.06 | 61.55 | 78.43 | 46.79 | 72.75 |
|---|
| WDASS | 84.01 | 63.78 | 64.78 | 74.23 | 55.63 | 67.84 |
|---|
| OURS | 85.47 | 75.23 | 67.40 | 80.01 | 62.12 | 75.36 |
|---|
| Supervised | 85.89 | 77.54 | 81.64 | 81.62 | 79.81 | 80.26 |
|---|
Table 4: Adaptation results on camouflaged object datasets.
| Method | CHAMELEON | CAMO | COD10K |
|---|
| box | point | poly | box | point | poly | box | point | poly |
|---|
| Direct | 51.32 | 39.37 | 45.78 | 62.72 | 57.43 | 50.85 | 66.32 | 63.61 | 40.04 |
|---|
| TENT | 65.48 | 54.53 | 53.06 | 71.24 | 59.59 | 60.29 | 69.36 | 61.94 | 43.36 |
|---|
| SHOT | 68.60 | 62.47 | 54.36 | 71.61 | 62.78 | 58.72 | 69.09 | 65.25 | 42.38 |
|---|
| Soft Teacher | 65.92 | 44.17 | 46.72 | 62.30 | 48.64 | 51.26 | 66.32 | 50.04 | 32.27 |
|---|
| TRIBE | 71.00 | 52.80 | 54.99 | 66.00 | 61.97 | 60.54 | 67.84 | 63.62 | 42.75 |
|---|
| DePT | 54.48 | 33.46 | 42.47 | 55.44 | 33.07 | 48.63 | 59.32 | 34.06 | 35.51 |
|---|
| WDASS | 71.91 | 62.40 | 56.80 | 71.25 | 63.39 | 62.29 | 71.42 | 65.61 | 43.93 |
|---|
| OURS | 75.94 | 74.00 | 66.83 | 73.42 | 65.55 | 62.90 | 71.93 | 70.55 | 45.87 |
|---|
| Supervised | 78.05 | 85.86 | 68.38 | 79.17 | 77.01 | 67.12 | 78.06 | 78.44 | 64.90 |
|---|
Table 5: Adaptation results on robotic image datasets.
| Method | OCID | OSD |
|---|
| box | point | poly | box | point | poly |
|---|
| Direct | 86.35 | 71.41 | 72.81 | 87.62 | 78.86 | 80.77 |
|---|
| TENT | 87.77 | 66.61 | 77.53 | 88.10 | 80.53 | 87.85 |
|---|
| SHOT | 88.06 | 74.39 | 76.25 | 88.09 | 80.52 | 87.86 |
|---|
| Soft Teacher | 84.98 | 68.46 | 73.75 | 90.41 | 80.49 | 87.00 |
|---|
| TRIBE | 86.77 | 67.86 | 76.50 | 90.42 | 80.54 | 87.84 |
|---|
| DePT | 82.00 | 56.52 | 70.92 | 81.84 | 69.06 | 82.50 |
|---|
| WDASS | 87.68 | 77.13 | 76.70 | 88.07 | 80.52 | 88.19 |
|---|
| OURS | 88.09 | 80.14 | 77.41 | 92.11 | 80.51 | 89.72 |
|---|
| Supervised | 91.24 | 89.22 | 79.23 | 92.14 | 82.41 | 90.83 |
|---|
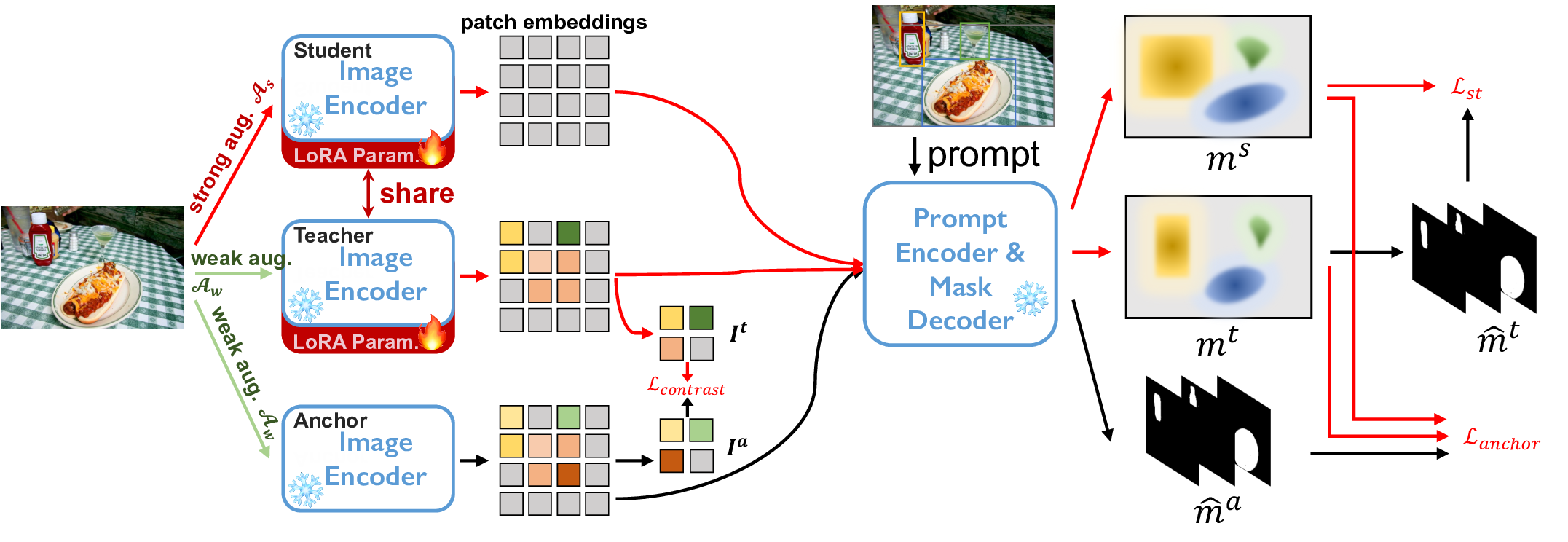
Ablation studies of the proposed weakly supervised adaptation method on COCO dataset.
| Weak Sup. |
Self-Train. |
Anchor |
Cont. Loss |
box |
point |
poly |
| original SAM | 74.29 | 56.36 | 65.42 |
| ✓ | ✓ | ✓ | | 58.88 | 32.51 | 55.03 |
| ✓ | ✓ | | ✓ | 79.65 | 57.25 | 70.49 |
| ✓ | ✓ | ✓ | ✓ | 62.95 | 22.87 | 56.91 |
| ✓ | ✓ | ✓ | 80.12 | 62.09 | 72.33 |
| ✓ | ✓ | ✓ | 76.18 | 47.63 | 70.44 |