
Multimodal AI · Generative Models · Computer Vision
Haojie Zhang
M.Sc. student at South China University of Technology, working on generative models, multimodal intelligence, and foundation vision systems.
About
Research across generation, multimodal reasoning, and foundation vision models.
I am currently an M.Sc. student in Information and Communication Engineering at South China University of Technology (SCUT), advised by Prof. Kui Jia and Dr. Xun Xu. I previously received my B.Eng. in Information Engineering (Innovation Class) from SCUT with distinction in 2023. From April 2024 to November 2024, I was a visiting student at the Department of Automation, Tsinghua University, where I worked with Prof. Jianhua Tao.
My long-term goal is to bridge perception, understanding, and imagination in intelligent systems. Recent work includes talking video synthesis, unified multimodal vision tasks, segmentation foundation model adaptation, and multimodal evaluation benchmarks.
Generative Models
Diffusion models, controllable video generation, talking head synthesis, image editing.
Multimodal LLMs
Unified multimodal vision tasks, dense prediction with MLLMs, multimodal evaluation.
Foundational Vision
Segmentation foundation models, domain adaptation, semantic perception.
Selected Publications
Selected work across vision foundation models, generative video, and multimodal evaluation.
Foundational Vision Models
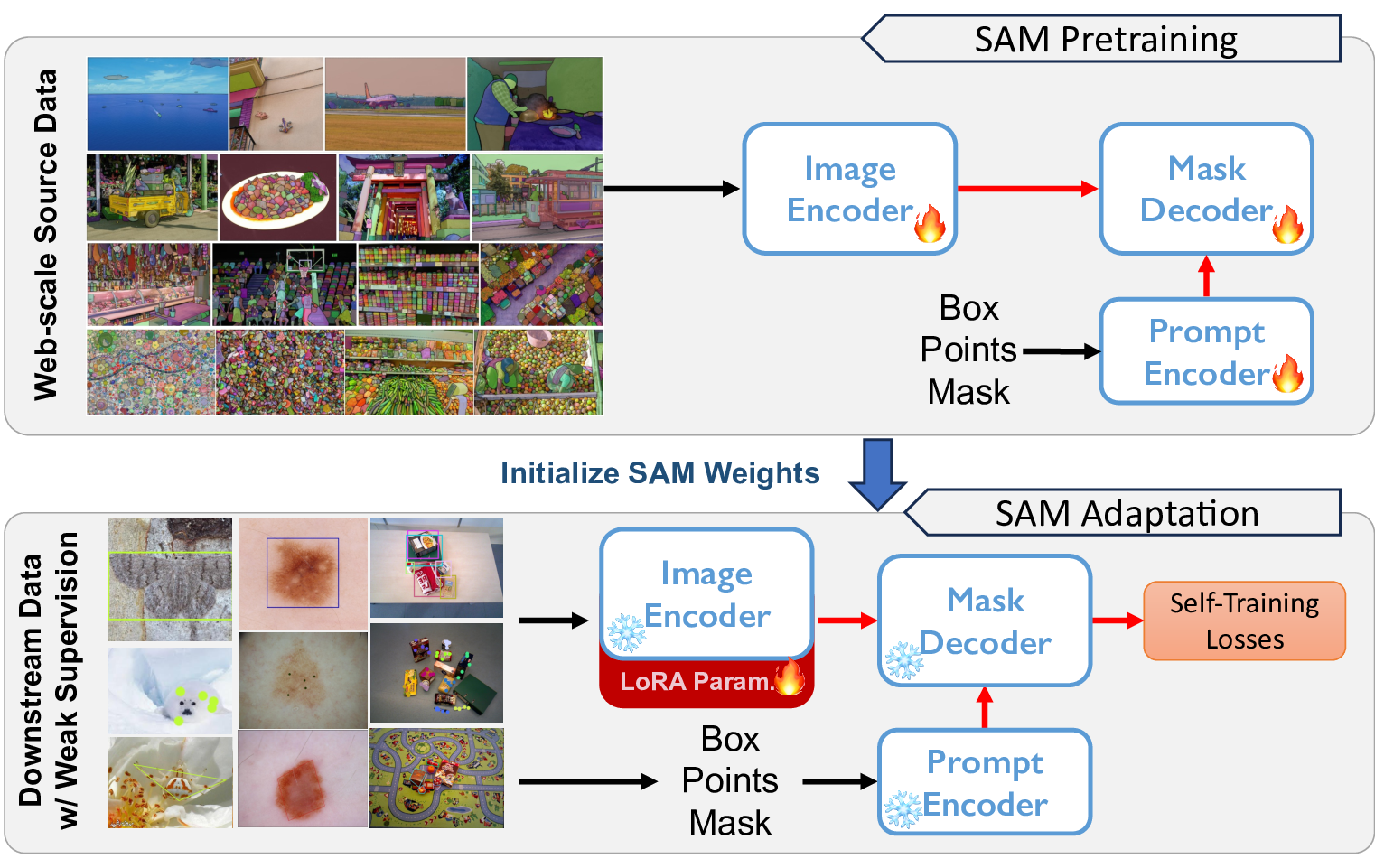
Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
Haojie Zhang, Yongyi Su, Xun Xu+, Kui Jia
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Paper | arXiv | Project | Code
- We propose WeSAM, a weakly supervised self-training framework with anchor regularization and low-rank adaptation, which enables efficient adaptation of foundation models (e.g., SAM) for diverse image segmentation tasks. WeSAM outperforms SAM and other state-of-the-art methods on five challenging benchmarks.
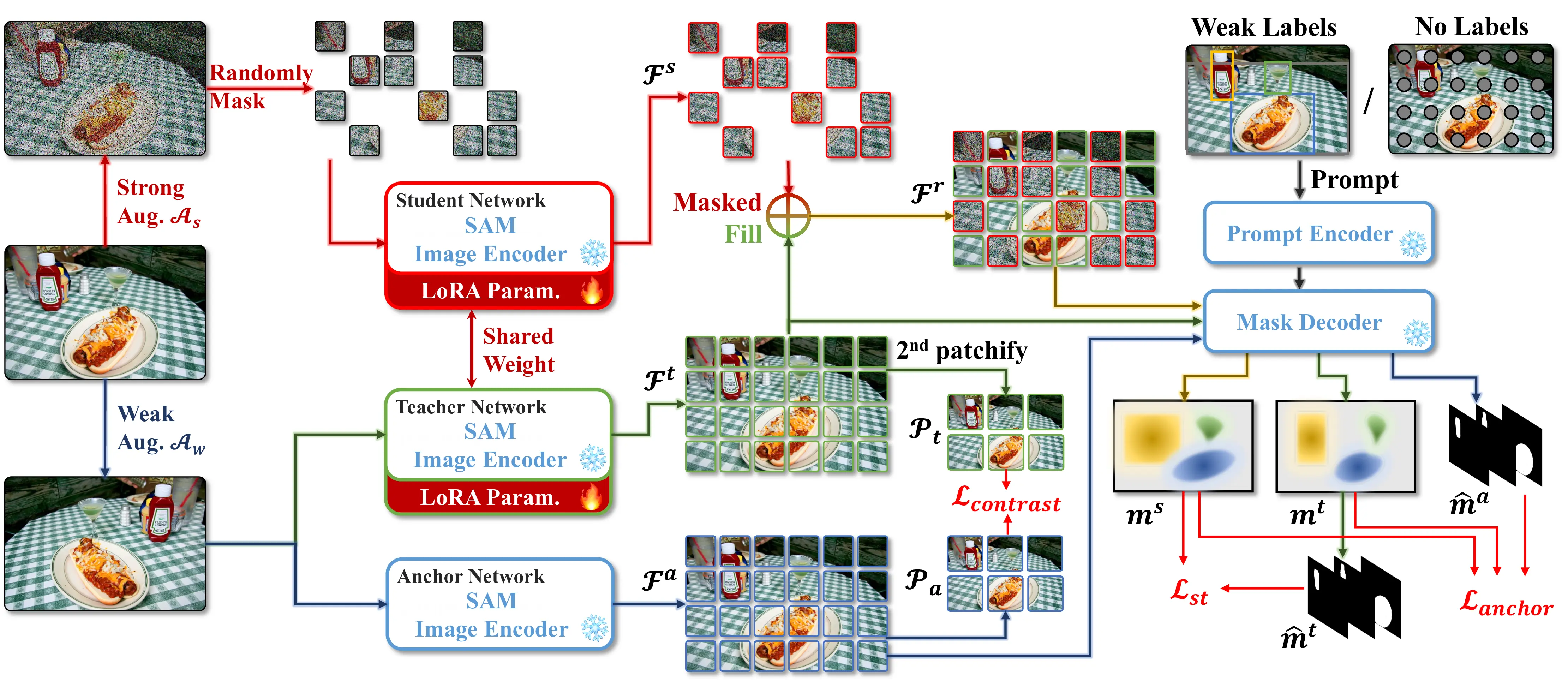
Improving the Generalization of Segmentation Foundation Models via Weakly-Supervised and Unsupervised Adaptation
Haojie Zhang, Yongyi Su, Nanqing Liu, Xulei Yang, Xiangyu Yue, Kui Jia, Xun Xu
Under review at IEEE TPAMI 2025
Preprint | Code
- We propose WeSAM++, which introduces patch-level contrastive loss for better feature alignment and incorporates Masked Image Modeling to enhance encoder consistency and robustness. Our method achieves superior generalization on unsupervised adaptation, open-vocabulary segmentation, and SAM2 adaptation.
Generative Models

Efficient Long-duration Talking Video Synthesis with Linear Diffusion Transformer under Multimodal Guidance
Haojie Zhang, Zhihao Liang, Ruibo Fu, Bingyan Liu, Zhengqi Wen, Xuefei Liu, Jianhua Tao, Yaling Liang
IEEE Transactions on Multimedia (TMM), 2026
arXiv | Code
- We propose LetsTalk, a diffusion transformer for audio-driven portrait animation. By leveraging DC-VAE and linear attention, LetsTalk enables efficient multimodal fusion and consistent portrait generation, while memory bank and noise-regularized training further improve the quality and stability of long-duration videos.

MuSS: A Large-Scale Dataset and Cinematic Narrative Benchmark for Multi-Shot Subject-to-Video Generation
Haojie Zhang, Di Wu, Bingyan Liu, Linjie Zhong, Yuancheng Wei, Xingsong Ye, Nanqing Liu
Under review
arXiv | Code
- We introduce MuSS, a large-scale cinematic multi-shot dataset and benchmark for subject-to-video generation, designed to evaluate narrative coherence, cross-shot identity consistency, and visual storytelling quality.
Multimodal Large Language Models

Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Yongyi Su*, Haojie Zhang*, Shijie Li, Nanqing Liu, Jingyi Liao, Junyi Pan, Yuan Liu, Xiaofen Xing, Chong Sun, Chen Li, Nancy F. Chen, Shuicheng Yan, Xulei Yang, Xun Xu
The International Conference on Learning Representations (ICLR), 2026
arXiv | Code
- We propose Patch-as-Decodable Token (PaDT), a unified multimodal paradigm that uses Visual Reference Tokens to let MLLMs directly generate diverse dense visual predictions, achieving strong performance across multiple perception tasks.
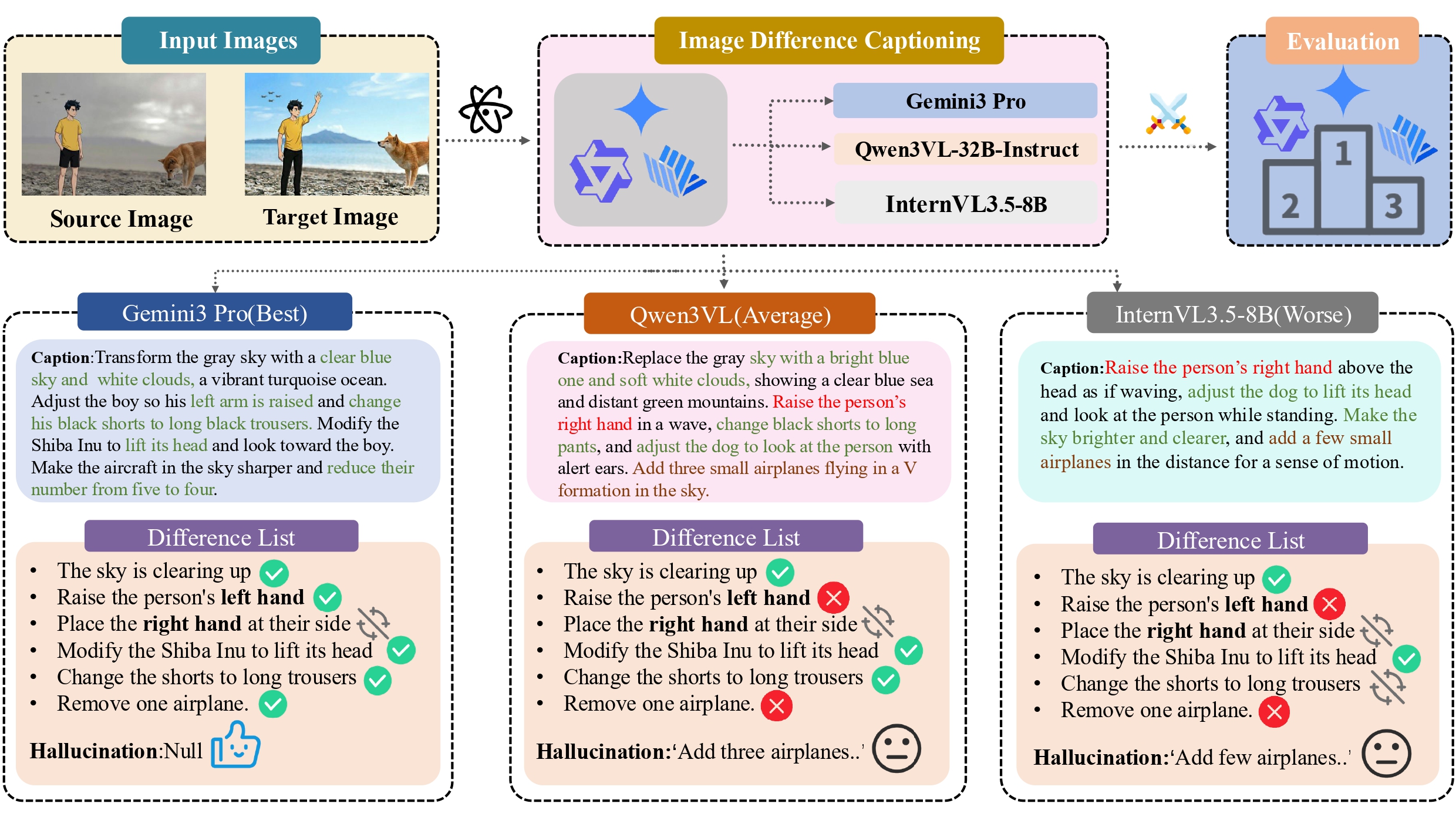
DiffCap-Bench: A Comprehensive, Challenging, Robust Benchmark for Image Difference Captioning
Yuancheng Wei*, Haojie Zhang*, Linli Yao, Lei Li, Jiali Chen, Tao Huang, Yiting Lu, Duojun Huang, Xin Li, Zhao Zhong
Under review
arXiv | Code
- We introduce DiffCap-Bench, a challenging benchmark for image difference captioning, together with an LLM-as-a-Judge evaluation protocol that aligns well with human judgment and supports downstream image editing data construction.
Education
Academic trajectory across SCUT and Tsinghua University.
-
2024.04 - 2024.11, Visiting Student, Department of Automation, Tsinghua University, Beijing
Advised by Prof. Jianhua Tao. -
2023.09 - 2026.06, MSc in Information and Communication Engineering, South China University of Technology, Guangzhou
Supervised by Prof. Kui Jia and collaborating with Dr. Xun Xu. -
2019.09 - 2023.06, B.Eng. in Information Engineering (Innovation Class), South China University of Technology, Guangzhou
Graduated with distinction, GPA 3.64/4.0, weighted average 86.1/100.
Internship Experience
Industry experience spanning video generation, vision systems, and multimodal applications.
- 2025.10 - 2026.03, Tencent Technology and Engineering Group, Hunyuan Team, Shenzhen
- 2025.04 - 2025.10, Tencent WeChat Business Group, WeChat Vision, Shenzhen
- 2024.12 - 2025.03, Tencent Interactive Entertainment Group, LIGHTSPEED, Shenzhen